
The Idea
Note
I’ve decided against open-sourcing this project. There is already an abundance of low-effort content on the internet as it is...Automagically create brainrot short-form content from reddit comment.
Like this or That or anything here.
If you are familiar with the Dead Internet Theory, this project was my personal experiment to see how much effort is required to recreate the type of videos you see on social media. This trend has become so widespread that Subway Surfer gameplay has even turned into a meme. The core concept is simple: pairing a random, visually engaging video—like a gameplay clip—with a voice-over to hold the attention of the average social media user just long enough for the video to “perform” well in terms of engagement.
Many content creators on Youtube promote running this kind of “Faceless” content machine. The idea is to create a faceless social media account and monetize it by generating an endless amount of content effortlessly. However, these YouTubers are often selling a dream and are making a significant profit promoting the very tools they recommend.
This led me to wonder: How difficult (or easy) would it be to automate content creation by repurposing Reddit comment threads and posting them on a faceless social media channel? With tools like FFmpeg, web scraping, and a few cloud APIs, I could likely automate the entire process of creating and uploading videos to YouTube with minimal manual efforts.
And that’s what I did.
The Plan
The plan was straightforward: build a CLI tool that takes a Reddit URL as input and generates a video that reads out the thread, layered over a visually stimulating background video. Since I enjoy working with Go, it was the natural language choice for this project.
With the Viper package, building user-friendly CLIs is easy. In no time, I had a functional base CLI with a decent interface.
|
|
With the boilerplate code out of the way, it was time to dive into the real stuff.
Sourcing content
The goal here is to avoid worrying about sourcing content, right? Why bother creating anything original? (Just kidding, of course.) Instead, let’s explore any copyright-free resources we can use and adapt to make them our own.
Reddit contains more content than anyone could read in a lifetime, but I had heard that the API is no longer as open as it once was. Rather than looking into the API, I decided to jump straight into web scraping—mainly because I thought it would be more fun.
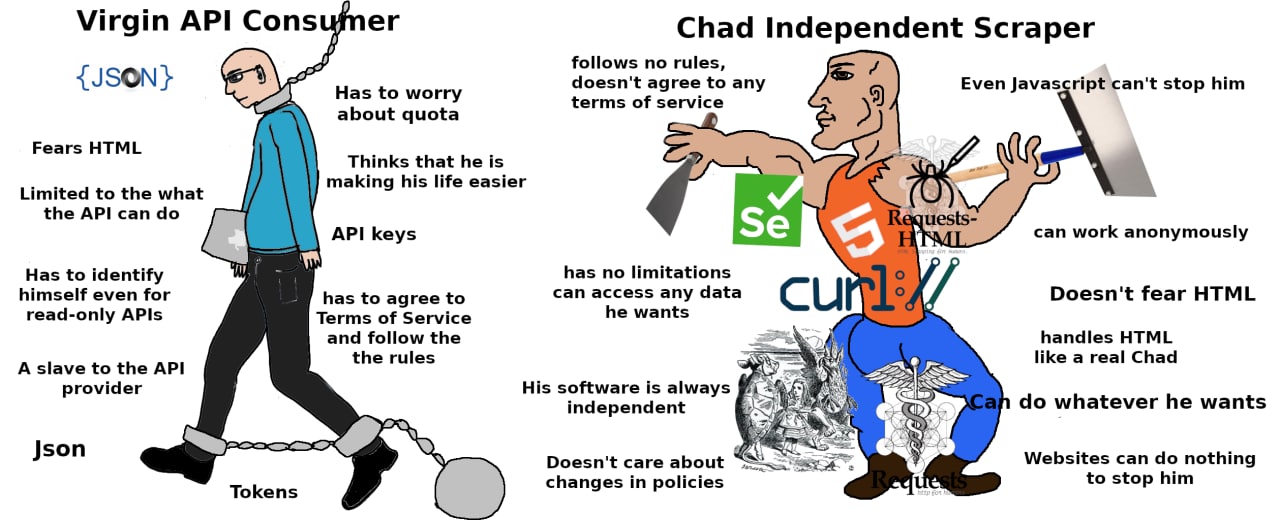
Using the goquery package, you can load an HTML page and navigate its elements with jQuery-like syntax. While it’s not groundbreaking or particularly exciting, it does get the job done.
Given an HTML page, I can construct a comment thread structure that follows the hierarchy of a Reddit comment thread. By limiting the depth to two, we only retrieve the title of the thread, the permalinked comment, and its replies.
Note
Sadly, this stopped working recently. Oh well...
|
|
For example, given this Reddit link, the script will scrape the content and output something like this:
Keeps this thread going and buzzfeed will have video ideas for years!
WHAT HAVE I DONE?
Dude, this has freakin made my day!
Copyright Free Gameplay Videos
Once again, the internet comes to the rescue. There are plenty of YouTube channels that focus on posting copyright-free gameplay videos intended for TikTok users. The idea is to build a small library of these videos, allowing Slopify to randomly select any video file from the folder, extract 60 seconds of footage, and roll with it.
I won’t go into the details of building the initial media library, but here are some helpful links:
Copyright Free Gameplay - Youtube
https://github.com/yt-dlp/yt-dlp
Building the blocks
Now that we have a method to parse dialogue and a collection of background footage, we need to put everything together.
Fortunately, we can leverage cloud APIs to generate audio and video
transcriptions. During each intermediate step of the video editing phase, files
are written to a “Workspace” folder at /tmp/slopify-$timestamp. This allows us
to recover audio or video files used to create the final product if needed. This
was especially useful for debugging ImageMagick’s “Title Card”
generation or addressing messy subtitles.
Speech
Talking over the video myself wouldn’t be as automated as I want it to be. Instead, I’ve decided to use Google’s Text-to-Speech (TTS) service. By using the GCP client, we can easily send a TTS service request and receive the generated voice file in return.
All gathered comments will be converted into audio files, which will then be concatenated into a single audio.mp3 file for use in the video.
|
|
Subtitles
You guessed it—I’m using the GCP Transcription API for this.
The GCP API requires that the video be uploaded to a Google Cloud Storage (GCS) bucket. I used some Terraform code to create this resource in my personal GCP project. Slopify uploads the video along with the corresponding voice-over audio, and the transcription API returns what it detects. The response includes a timestamp for every word spoken in the video, along with their respective timestamps.
From this information, we can build a SRT
File and have ffmpeg handled the
captions on the video.
|
|
Title Card
Simply displaying the video with word-for-word subtitles felt a bit bland, so I wanted to create a title card that would be visible while the title of the Reddit thread is being read. Using ImageMagick, I managed to create a square PNG containing the title text.
Meh, Good enough.
|
|
Actually editing the video together
This was actually the hardest part of creating Slopify. Programmatically assembling the video required learning how to use ffmpeg-go as well as FFmpeg itself. The package simplifies this task by providing bindings to help construct FFmpeg commands.
This code snippet demonstrates how to crop a video to match the shorter of the two input files: the gameplay video and the thread being read out by the TTS voice.
|
|
Now, wrap this with an API call to YouTube’s video upload API, and you can quickly generate videos in just a few minutes. However, the GCP API endpoint for uploading videos to YouTube has a quota limitation, allowing only six uploads per day unless you contact them to request an upgrade.
I really doubt my experiments would be considered valid enough to justify uploading shorts every hour of the day.
Conclusion
Well, in the end, it did work.
I had a lot of fun building this project, especially when I realized that it could actually function. It’s quite scary to think that someone could potentially weaponize such software and take over the internet. Who knows, this might already be happening. I wouldn’t be surprised at all.
YouTube actually filters out low-effort content, so my videos never ended up getting recommended to anyone (phew!) Anyone looking to make actual money with this approach would need to invest more effort into the editing—my basic FFmpeg edits felt pretty bland compared to what you typically find on TikTok.
For the sake of experimentation, I would definitely say it was worth the effort.
